Journal #Five [PRJ701] - Data Pipeline Infrastructure
![Journal #Five [PRJ701] - Data Pipeline Infrastructure](/assets/images/prj701-j5.jpg)
Data Pipeline Infrastructure
JOURNAL #FIVE [PRJ701]
Data Pipeline Infrastructure
Data Mapping
Data mapping across any organisation will often lead to data that is generated in several different forms. Application databases might produce CSV files for manual transformation before data warehouse ingestion, alternatively integrations can automation some or all of the ETL/ELT process.
The key to answering priority business questions is the information input to the sales application. To better understand what historical data is available and to uncover opportunities to improve the data input through the use of constraints and operational processes, an API has been deployed to read the data sets to discover relationships that could support the project OKR’s.
The API client used for this process utilised the representational state transfer (REST) conventions and has been designed to have a predictable URL structure. The client deploys the following standard HTTP features to return standard JSON that can be used to compare and relate data sets:
- POST
- GET
- PUT
- DELETE
REST is an architectural style for distributed hypertext systems that includes 6 guiding principles, or constraints. For an interface to be referred to as ‘RESTful’ the constraints must be satisfied. More information on REST architecture can be found here.
To perform the data mapping a collaborative API client, Insomnia was deployed that integrated with the sales software. Insomnia allows for easy and fast REST, SOAP, GraphQL and GRPC requests, communicating directly with the source. This was used to catch data relationships and identifiers that could support the data mapping process.
The following imagery shows a selection of the operations run against the API and the output in the Insomnia client.
N.B. Data of a sensitive nature has been redacted.
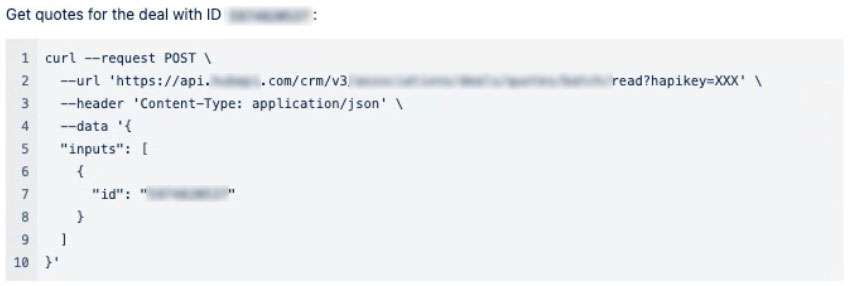

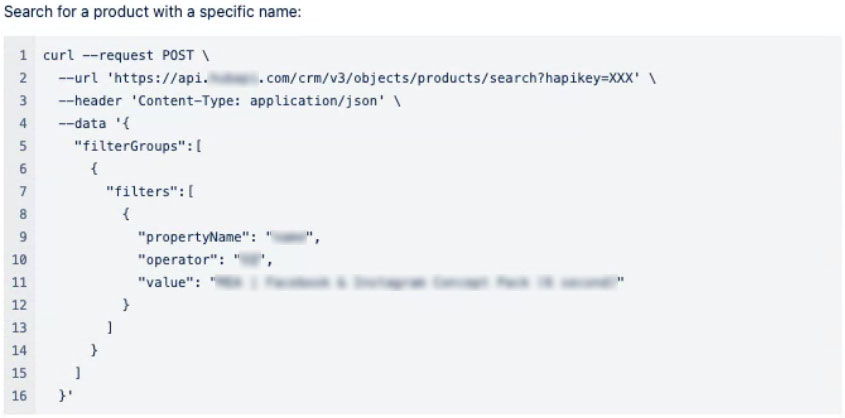
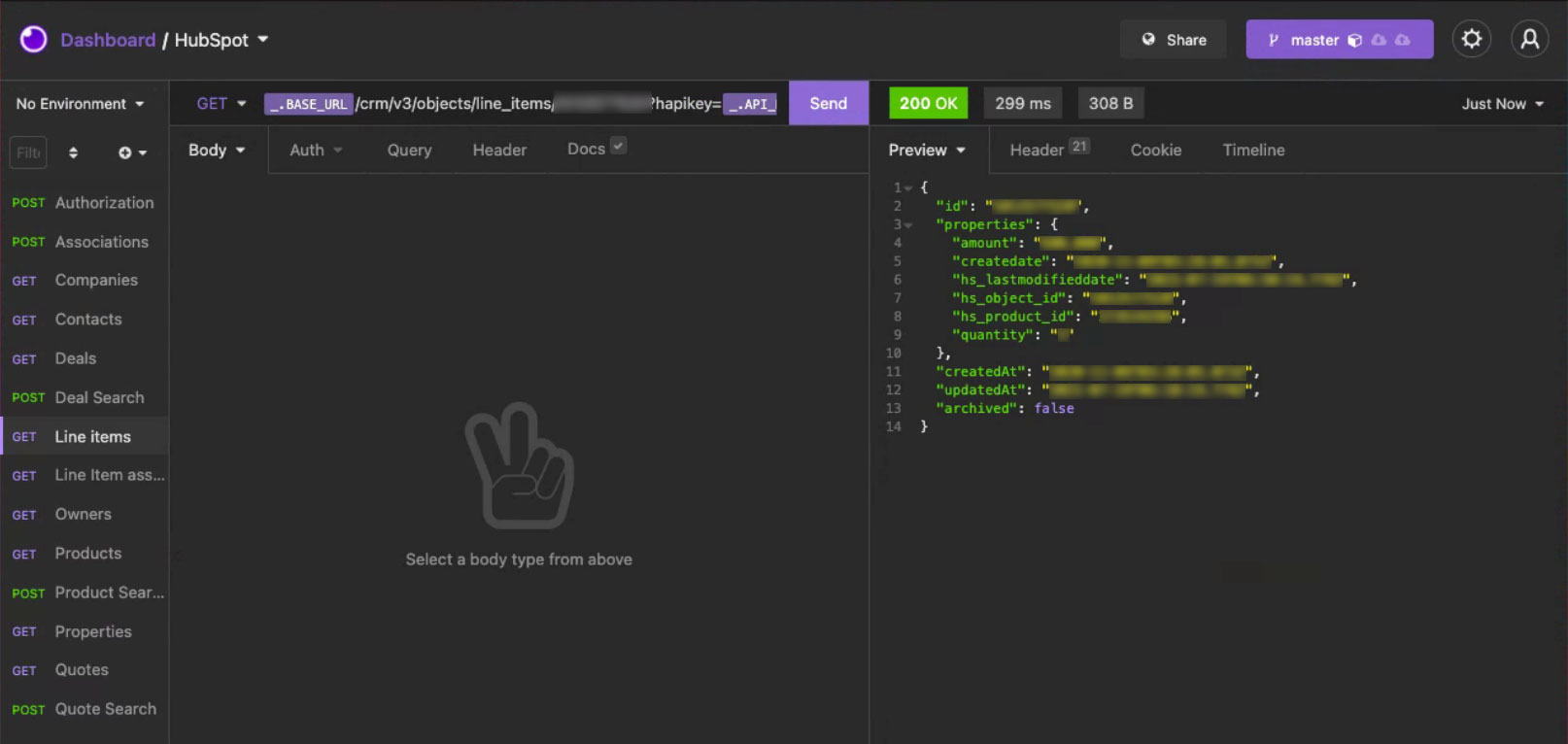
Data Warehouse
A meeting has taken place with the preferred cloud-based data warehouse provider, an OLAP database system that can be deployed for both data warehousing and data lakes. The provider deploys multi-cluster warehouse architecture that is better able to scale in comparison to competitor systems such as AWS Redshift and Azure.
Multi-cluster warehousing allows for the allocating of additional static or dynamic warehouses to increase the pool of resources, this means that queries don’t have to be queued until sufficient resources become available. The same properties are still supported when deploying a multi-warehouse environment, including:
- Setting the size of the data warehouse
- Scale the size of the data warehouse up or down to meet business needs
- Automatically suspend the running of the entire multi-cluster warehouse due to inactivity
- Automatically resume the multi-cluster warehouse on submission of new queries
Tables in the data warehouse are divided automatically into micro-partitions, these are contiguous storage units of uncompressed data between 50MB and 500MB. The individual micro-partitions are organised in columns containing mapped rows that form a group, the data is ordered as it is loaded to the data warehouse. The benefits of micro-partitions are as follows:
- Automatically-derived, meaning there is no user maintenance required and no requirement to explicitly define up-front
- Allows for faster more efficient DML (DELETE, UPDATE, MERGE queries) as a result of the small size of each micro-partition
- As columns are independently stored, scanning is more efficient
- Columns are automatically compressed within the micro-partitions
Time Travel is a feature that creates a copy of the data warehouse that is stored in the cloud at the point time a table is updated, making it possible to select data from the previous day, week, or month should a future update or input error result in data loss. This feature is paid for as part of the storage costs and has the following specific functionality:
- When data is updated the pointer shifts to that new partition, the old one is then retained for the period set for the time travel deployment
- Time Travel copy’s, or ‘deltas’, allows for duplicates to be stored for another reason, with replication to another account, or stored in another location such as Frankfurt or London etc. this acts as a complete replica of the account in another geolocation
- The cost associated with the feature relates to both compute and storage in the other geolocation, this can act as a cheap near time backup (read-only) or as a hot switch (failover) depending on the subscription model
The provider offers several benefits and features that meet the use case as follows:
- Functionality that allows for big compute usage when needed, then the ability to scale down to save money
- Implementation of row-level security, for example, territories could be secured against sales teams that operate in that region
- Single-sign-on (SSO) can be utilised as the authentication method for the provider and integrated with several popular data analytics tools, depending on the SSO provider user and roles can be synced, alternatively added manually
- Deploy role-based masking, for example, you may want to include a policy for PII concerning email addresses that allows SYSADMINs to see the data subjects name in the email, whilst restricting standard users to only view the domain part of the email address
- Development clone of the production data warehouse plus cloning of the metadata, thus creating two databases, ensuring an update of the dev clone doesn’t affect production and vice versa
- Clones can be set as a point in time snapshot and used as a monthly backup that can be referred back to if needed
- Masking can be utilised to hide PII or personal data, data can be masked on the fly such as names, companies etc. through a process of tokenising, encrypting, or hash functions
Further data warehouse information will be provided in future journals following a demonstration meeting, this should improve the clarity of the practical applications of the product.
HubSpot APIs - Getting started. (n.d.). Retrieved August 26, 2021, from https://developers.hubspot.com/docs/api/overview
Micro-partitions & Data Clustering—Snowflake Documentation. (n.d.). Retrieved August 26, 2021, from https://docs.snowflake.com/en/user-guide/tables-clustering-micropartitions.html
Multi-cluster Warehouses—Snowflake Documentation. (n.d.). Retrieved August 26, 2021, from https://docs.snowflake.com/en/user-guide/warehouses-multicluster.html
The API Design Platform and API Client. (n.d.). Retrieved August 26, 2021, from https://insomnia.rest/
Understanding & Using Time Travel—Snowflake Documentation. (n.d.). Retrieved August 26, 2021, from https://docs.snowflake.com/en/user-guide/data-time-travel.html
What is REST. (n.d.). REST API Tutorial. Retrieved August 26, 2021, from https://restfulapi.net/