Journal #Four [PRJ701] - Data Anonymisation
![Journal #Four [PRJ701] - Data Anonymisation](/assets/images/prj701-j4.jpg)
Data Anonymisation
JOURNAL #FOUR [PRJ701]
Data Anonymisation
Daily Standups
The primary focus for the daily standups has been on attempting to clarifying where the required data is located, in what form, and if there is sufficient information to allow the team to meet the business requirements.
To assist in the identification of the available data a technical process of accessing the sales software API has been undertaken. The purpose is to map data points to discover where relationships exist that can help answer several business questions. In this instance, the specific use case is to calculate the gross margin on deals made as they relate to products that form the deal, split by sales price against and identified by individual sales representatives.
Insomnia is being used to access the data sets to relate products to deals through unique identifiers. The process has produced positive results including the discovery of keys that establish relationships between data sets. It is not uncommon when performing tasks such as these that further ways to improve the quality of the data being input into the system are recognised, and indeed there are administrative functions that can be placed on the system that can enforce data constraints on inputs going forward. Once the data is mapped this can be loaded into the data warehouse to provide relevant analytics for business units.
The Anonymisation Process
An investigation has taken place into anonymising data to ensure the organisation is capable of maintaining its ongoing commitments to GDPR compliance. Although the GDPR specifically regulates data pseudonymisation, anonymisation can be effectively utilised as it negates the need to consider the regulations directly. This is achieved through the anonymising of data in such a way that it is safeguarded, meaning it cannot be inferred who, from the anonymised data, is the data subject. The effect of this process is that it is no longer defined as PII or ‘personal data’, therefore it falls outside the scope of the GDPR.
It is important to note that data anonymisation is a more complex process than pseudonymisation, and the options available require different considerations. There are several tools available to achieve data anonymisation that utilise the k-anonymity protection model and these include several open source products:
- Anonimatron
- Amnesia
- ARX Data Anonymization Tool
An initial attempt was made to test the process using the opensource Anonimatron, however, within the technical environment established to ensure the safety and security of the wider IT infrastructure, the setup of the software failed. There was, unfortunately, insufficient documentation available for adequate troubleshooting.
Amnesia is a cloud-based service that would best meet the IT infrastructure of the wider organisation. However, further investigation would be necessary to determine the geolocation of the cloud infrastructure to ensure that regulatory compliance could be maintained with regards to transferring information to data centres outside the EU or safe harbour countries to perform the transformation, this would negate its intended purpose.
Although the test data being transformed as part of the exercise was readily available from online sources, ARX was chosen to test the process. This is an open-source package that could be installed locally in a sandbox environment to confidently separate it from the wider system to meet security obligations.
Practical Application - k-Anonymity
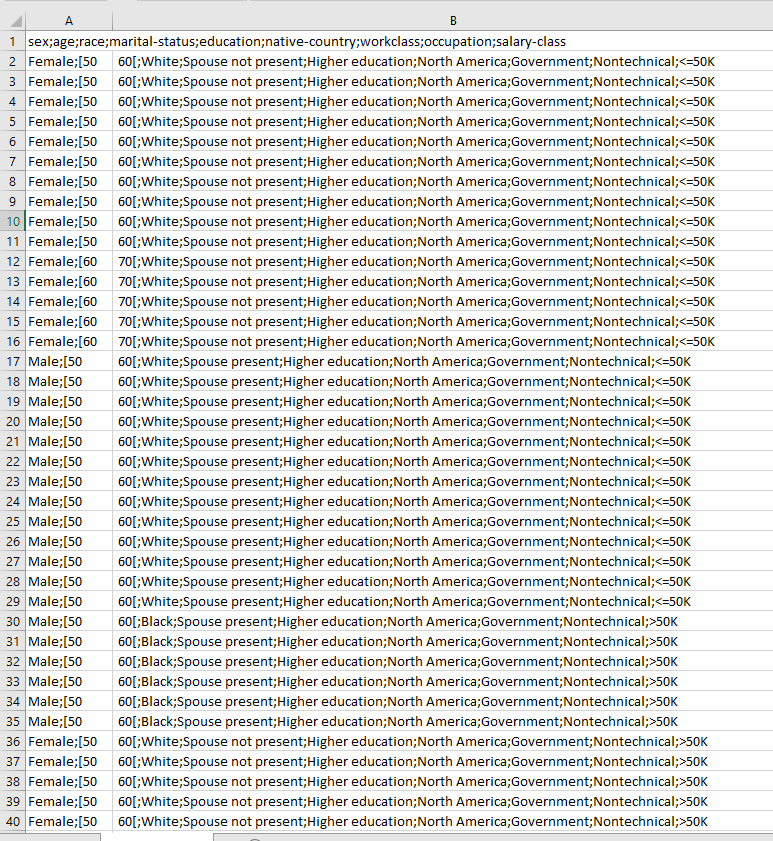
The data was imported from a CSV file and analysed, which included relevant metadata to begin the transformation process. The test data set included specific fields that had the potential to identify a data subject as defined by the GDPR.
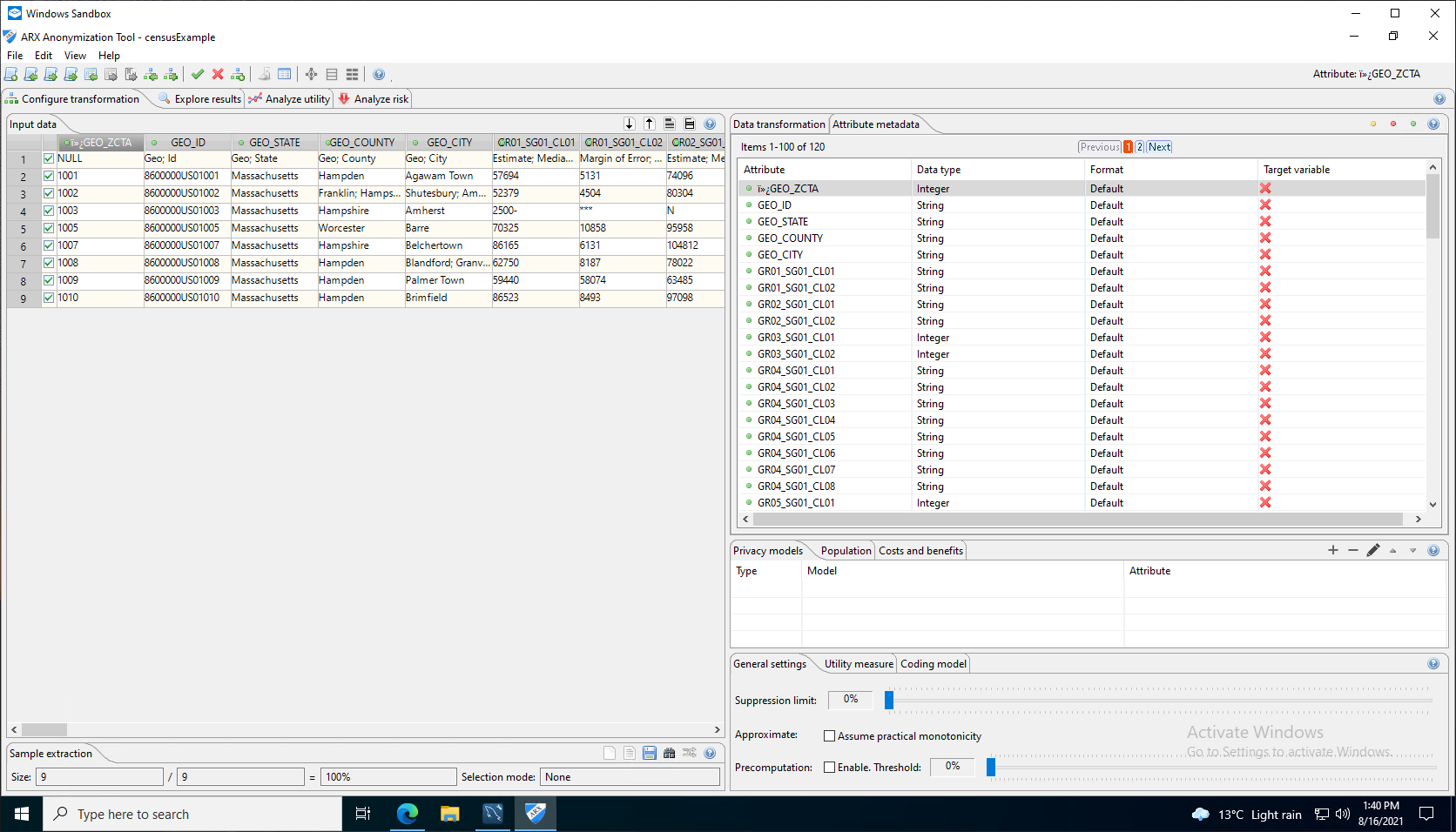
The process of data transformation involves some decision making. Firstly, it must be sufficiently transformed to ensure that re-identification cannot be performed without significant effort, which is recognised under the GDPR. Secondly, it must remain in a state that allows a business or organisation to obtain valuable analytics. The process can also be used as part of the wider extract, transform and load (ETL) process of a Data Anonymisation Process, the preferred method when considering data privacy.
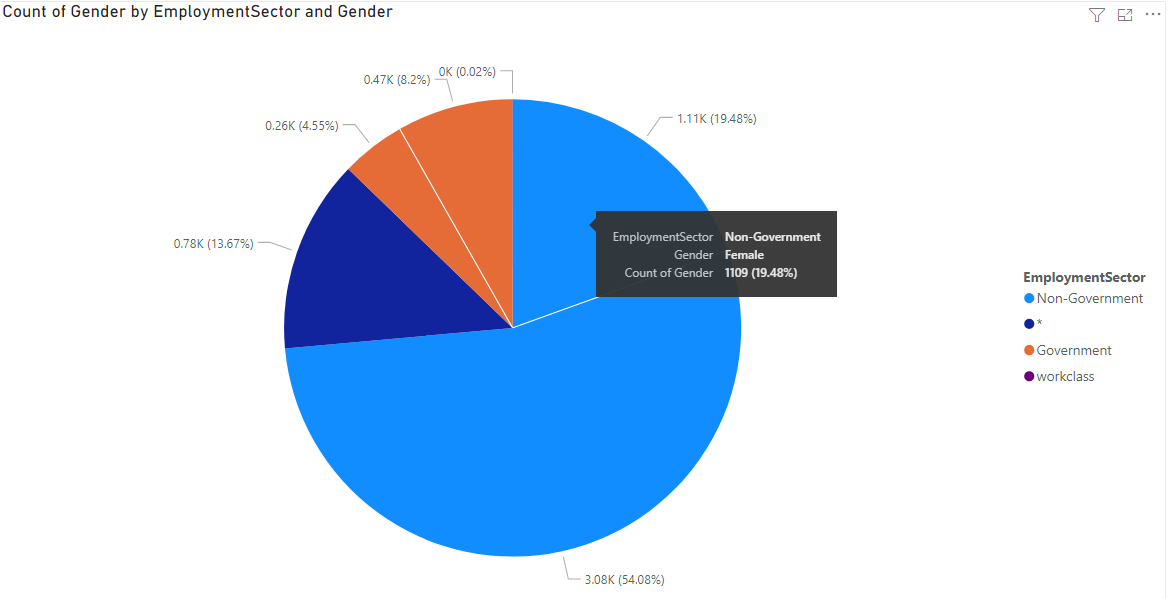
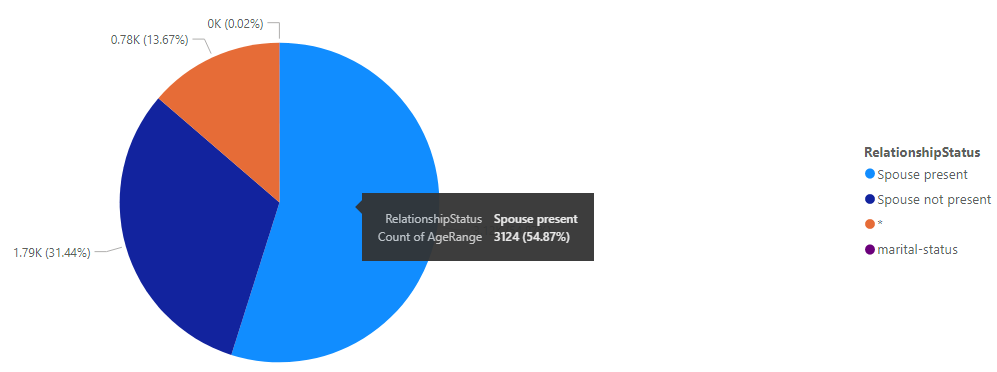
The following image shows the output data, making note of the age column data shows the generalised data output that has been transformed from producing specific ages to an age range meaning it can no longer be used to identify a specific data subject. Information relating to marital status, education and work class has been suppressed as part of this process, suppression removes the data that might be considered irrelevant for producing valuable data analytics. In this specific example, spousal information has been transformed to merely identify those individuals that have spouses present, and those that do not. The same principle has been applied to education, work class and occupation as visible in the example produced.
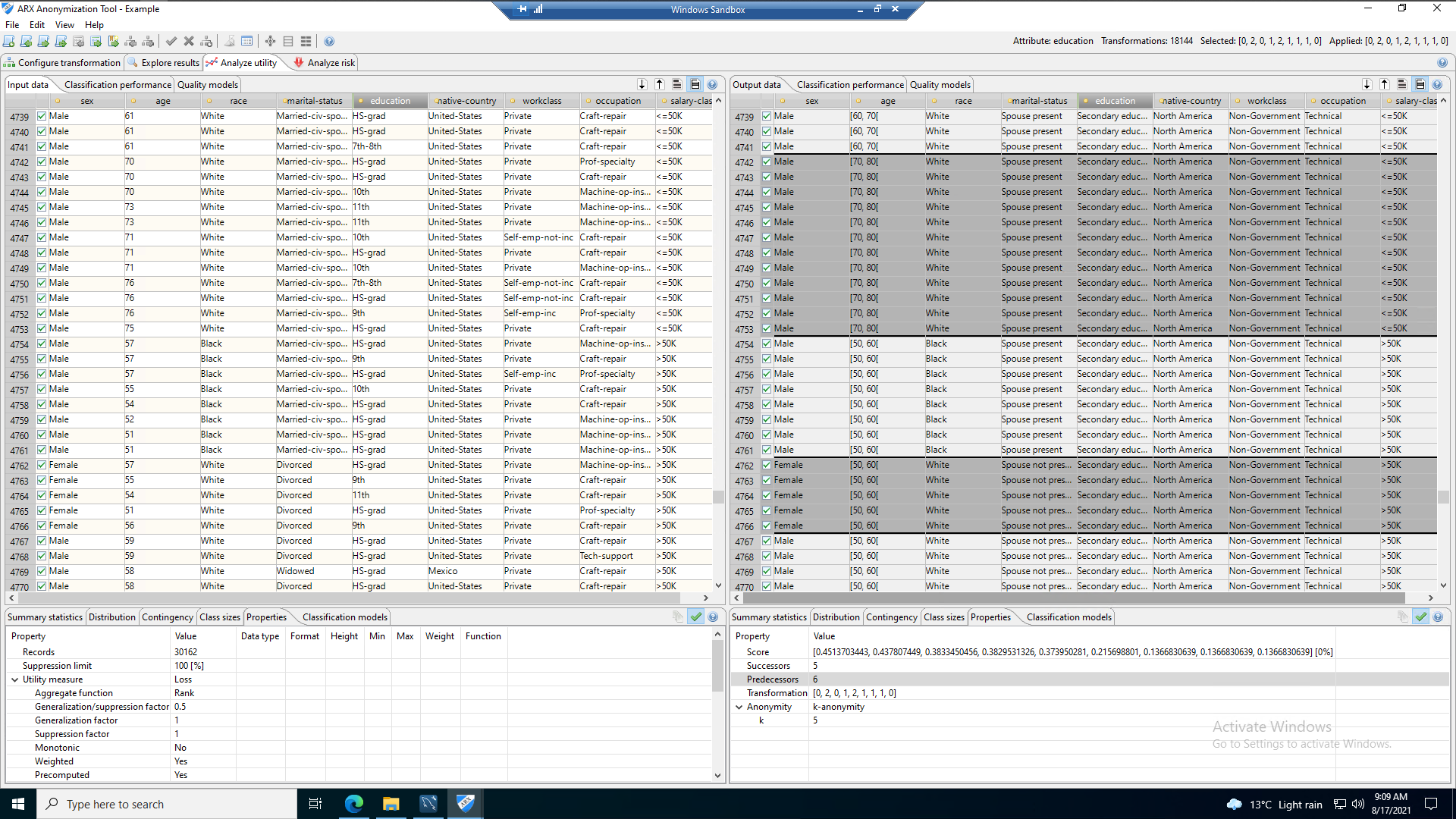
As part of the ARX package, metrics and analytics are included that help identify the success of the anonymisation process, the following images show some of the results of the data transformation represented in chart form. These can be used to evidence compliance with the internal organisational processes and regulatory frameworks.
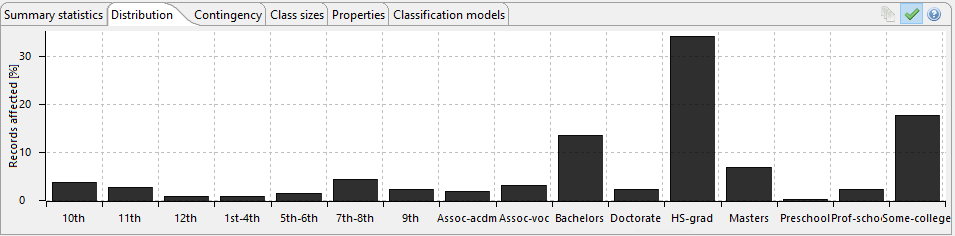
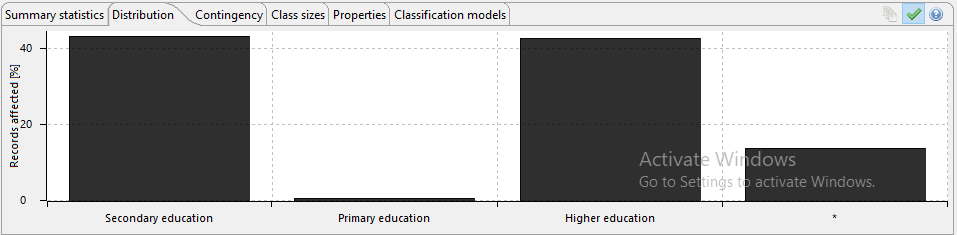
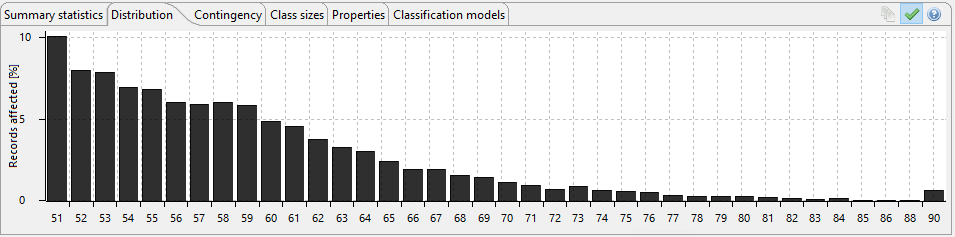
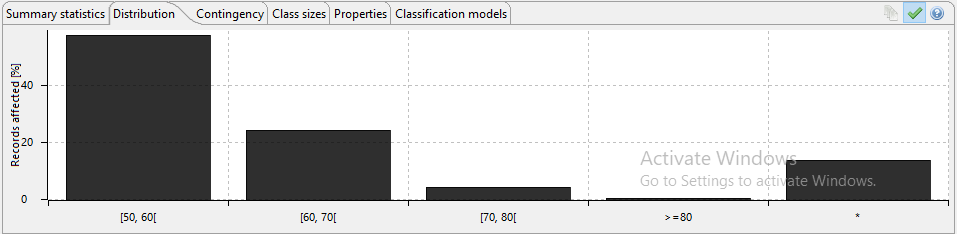
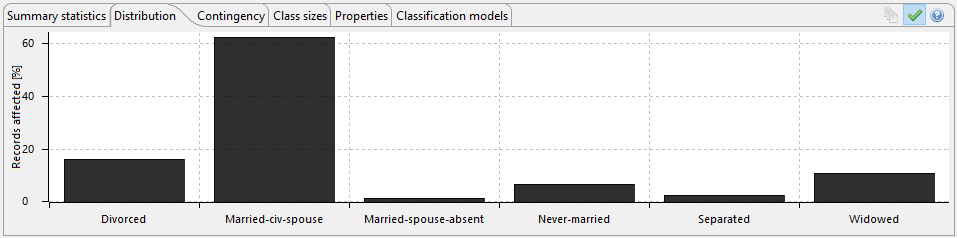
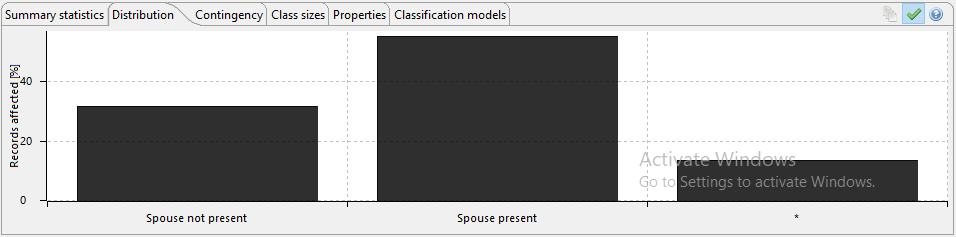
The following images show the anonymity score, which can be adjusted as required. This feature allows a comparison to be made that determines the degree of transformation required to satisfy the use case.
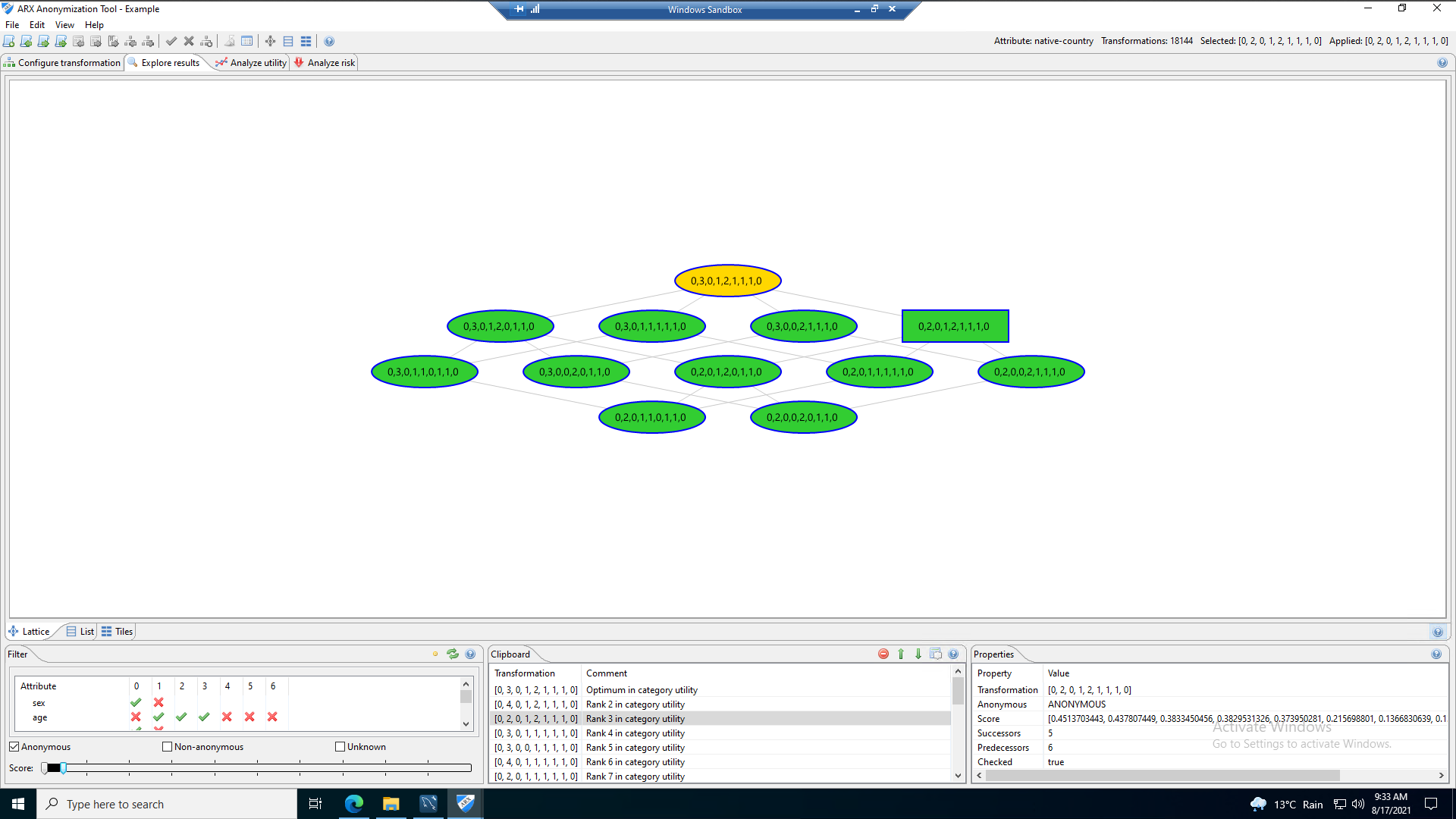
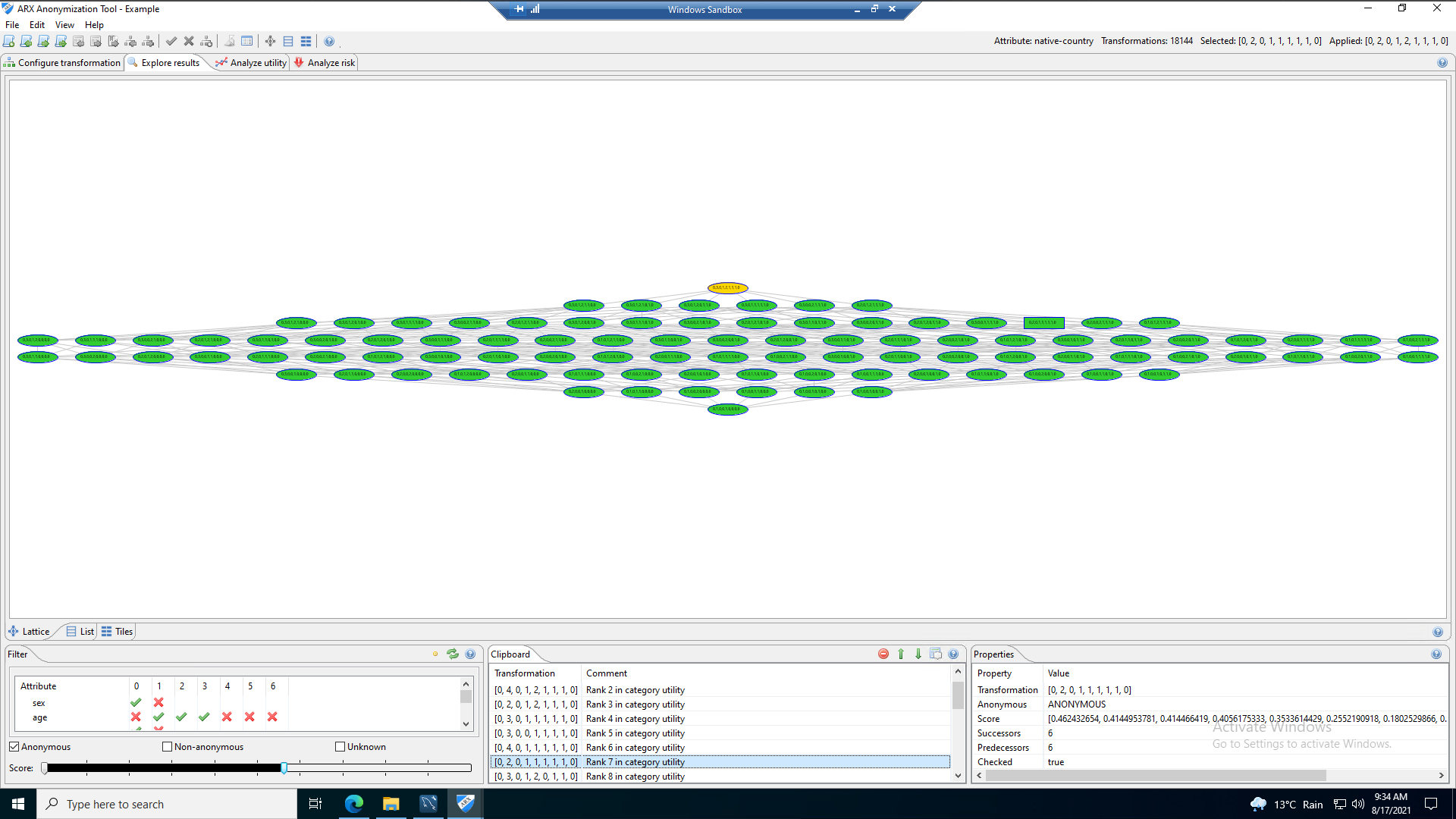
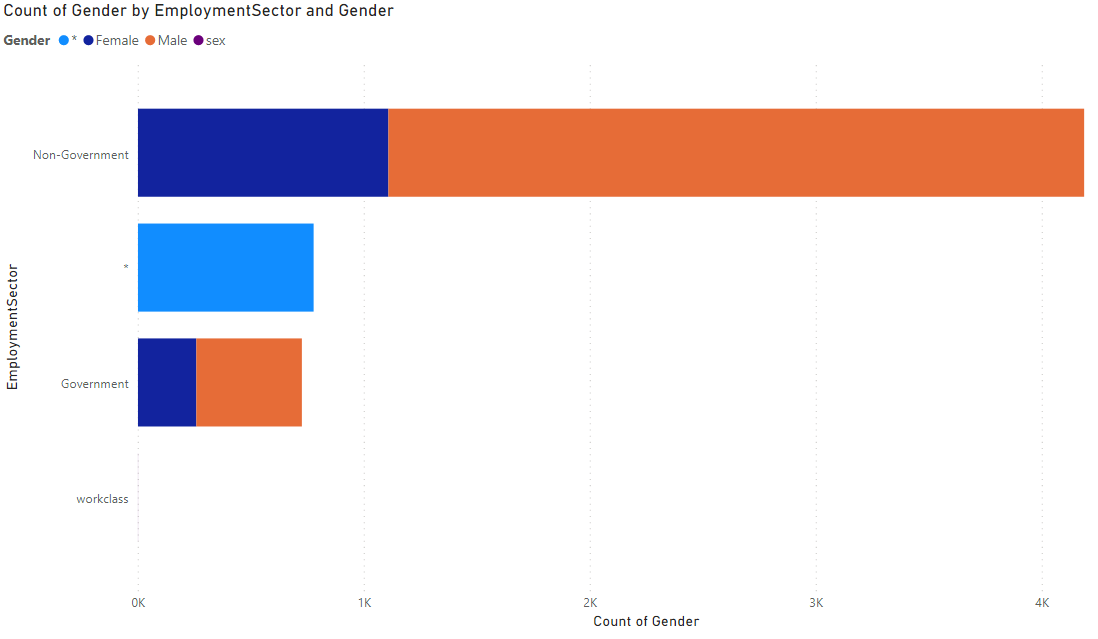
Upon completion of a full assessment of the data ensuring it is satisfactory, it can be exported as a CSV file that can be uploaded to a data warehouse. Data analytics can be performed, in this instance, Microsoft Power BI, to show the level of information that can still be gained from the data set, despite the fact data is now grouped at a granularity that obscures the unit record resulting from the k-anonymity process.
ARX - Data Anonymization Tool. (n.d.). Introduction to the ARX Data Anonymization Tool. Retrieved August 20, 2021, from https://www.youtube.com/watch?v=N8I-sxmMfqQ
ARX - Data Anonymization Tool - A comprehensive software for privacy-preserving microdata publishing. (n.d.). Retrieved August 20, 2021, from https://arx.deidentifier.org/
Data Visualization - Microsoft Power BI. (n.d.). Retrieved August 20, 2021, from https://powerbi.microsoft.com/en-us/
Dimakopoulos, M. T., Dimitris Tsitsigkos and Nikolaos. (n.d.). Amnesia Anonymization Tool—Data anonymization made easy. Retrieved August 20, 2021, from https://amnesia.openaire.eu/
GDPR compliant testing. (n.d.). Anonimatron. Retrieved August 20, 2021, from https://realrolfje.github.io/anonimatron/
K-Anonymity: Everything You Need to Know (2021 Guide). (2021, April 14). Immuta. https://www.immuta.com/articles/k-anonymity-everything-you-need-to-know-2021-guide/
The API Design Platform and API Client. (n.d.). Retrieved August 20, 2021, from https://insomnia.rest/