Journal #Two [DAT701] - Data Warehouse DDL
![Journal #Two [DAT701] - Data Warehouse DDL](/assets/images/dat701-j2.jpg)
Data Warehouse DDL
JOURNAL #TWO [DAT701]
Data Warehouse DDL
Data Definition Language DDL
Figure 3 is a view of the data definition language (DDL) used to meet the schema design. Column data types match the attributes in the FinanceDB database. A primary key constraint has been created against the date key in the DimDate table. Primary key constraints have not been created on the other dimension tables because the fact table granularity is such that the relationship references will replicated in these tables, instead a clustered index has been created against these references.
-- >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
-- Create tables procedure
drop procedure if exists create_tables
go
create procedure create_tables
as
begin
drop table if exists FactSalePerformance;
drop table if exists FactSaleOrder;
drop table if exists DimDate;
drop table if exists DimProduct;
drop table if exists DimSalesLocation;
drop table if exists DimSalesPerson;
-- DimDate
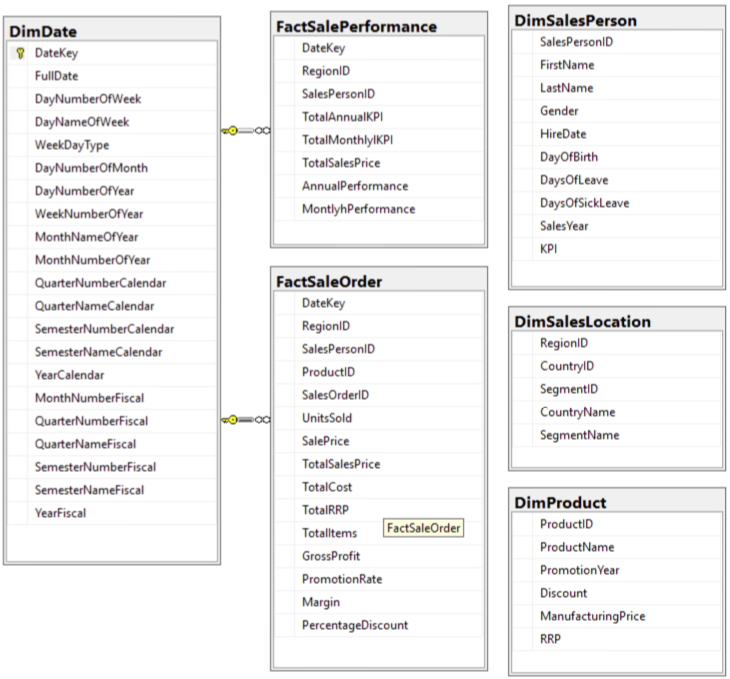
create table DimDate
(
DateKey int not null,
FullDate date not null,
DayNumberOfWeek tinyint not null,
DayNameOfWeek nvarchar(10) not null,
WeekDayType nvarchar(7) not null,
DayNumberOfMonth tinyint not null,
DayNumberOfYear smallint not null,
WeekNumberOfYear tinyint not null,
MonthNameOfYear nvarchar(10) not null,
MonthNumberOfYear tinyint not null,
QuarterNumberCalendar tinyint not null,
QuarterNameCalendar nchar(2) not null,
SemesterNumberCalendar tinyint not null,
SemesterNameCalendar nvarchar(15) not null,
YearCalendar smallint not null,
MonthNumberFiscal tinyint not null,
QuarterNumberFiscal tinyint not null,
QuarterNameFiscal nchar(2) not null,
SemesterNumberFiscal tinyint not null,
SemesterNameFiscal nvarchar(15) not null,
YearFiscal smallint not null
constraint PK_DimDate primary key clustered
(
DateKey asc
)
)
-- DimProduct
create table DimProduct
(
ProductID tinyint,
ProductName varchar(24),
PromotionYear int
);
-- exec sp_helpindex 'DimProduct';
drop index if exists idx_product on DimProduct;
create clustered index idx_product
on DimProduct
(ProductID);
-- DimSalesLocation
create table DimSalesLocation
(
RegionID smallint,
CountryID tinyint,
SegmentID tinyint,
CountryName varchar(56),
SegmentName varchar(48)
);
-- exec sp_helpindex 'DimSalesLocation';
drop index if exists idx_saleslocation on DimSalesLocation;
create clustered index idx_saleslocation
on DimSalesLocation
(RegionID);
-- DimSalesPerson
create table DimSalesPerson
(
SalesPersonID smallint,
FirstName varchar(64),
LastName varchar(64),
Gender varchar(20),
HireDate date,
DayOfBirth date,
DaysOfLeave int,
DaysOfSickLeave int
);
-- exec sp_helpindex 'DimSalesPerson';
drop index if exists idx_salesperson on DimSalesPerson;
create clustered index idx_salesperson
on DimSalesPerson
(SalesPersonID);
drop index if exists idx_salespersonname on DimSalesPerson;
create nonclustered index idx_salespersonname
on DimSalesPerson
(FirstName, LastName);
-- FactSalesPerformance
create table FactSalePerformance
(
DateKey int not null foreign key references DimDate([dateKey]),
SalesPersonID smallint,
RegionID smallint,
TotalAnnualKPI float,
AnnualSalesPrice float,
AnnualPerformance float,
TotalMonthlylKPI float,
MonthlySalesPrice float,
MonthlyPerformance float
);
-- exec sp_helpindex 'FactSalePerformance';
drop index if exists idx_fsp_group on FactSalePerformance;
create nonclustered index idx_fsp_group
on FactSalePerformance
(SalesPersonID, RegionID);
create table FactSaleOrder
(
DateKey int not null foreign key references DimDate([dateKey]),
SalesOrderID bigint,
RegionID smallint,
SalesPersonID smallint,
ProductID tinyint,
UnitsSold smallint,
SalePrice float,
TotalSalesPrice float,
TotalCost float,
GrossProfit float,
TotalRRP float,
TotalItems int,
PromotionRate int,
Margin float,
PercentageDiscount float
);
-- exec sp_helpindex 'FactSaleOrder';
drop index if exists idx_fsp_group on FactSaleOrder;
create nonclustered index idx_fso_group
on FactSaleOrder
(SalesPersonID, RegionID, ProductID);
end;
go
-- >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
-- Execute create tables procedure
exec create_tables;
go
Indexes
The DDL includes clustered and non-clustered indexes that have been created with consideration made to the results produced in Assignment 1. The DimDate table contains a clustered index against the date key. Currently, there is no requirement to create non-clustered indexes for this table. However, with the data loaded into the warehouse, performance tests can be run to determine if a non-clustered index would be beneficial against the MonthNumberOfYear, given the granularity of the data month is likely to be the most commonly used column to perform queries that are capable of answering the business questions.
Clustered indexes have been created for the remaining dimension tables against the relevant primary keys from the OLTP database. Due to the size of the data set concerning these tables, it is anticipated that there will be no further requirement to create further non-clustered indexes. However, as sales representatives First and Last names will be selected in the performance queries, to support query performance a non-clustered index has been created against these to future proof against a growing data set.
The fact tables contain clustered indexes that have been created in conjunction with table partitioning, this is detailed in the following sub-section. Non-clustered indexes have been created that include all relationship IDs that act as foreign key references to the dimension tables, with FactSaleOrder containing a further non-clustered index on SalesOrderID, which effectively acts as the key identifier for the orders contained in this fact table.
Table Partitioning
Table partitioning has been carefully applied against columns that are anticipated to be used most often for the analytical reporting, in this instance partitioning is performed against the date column included in both fact tables. The date column is an ideal candidate for table partitioning because it is low cardinality, having low distinct values concerning the number of rows contained in the column.
Two approaches to table partitioning have been considered, the first was partitioning using the built- in wizard available in SQL Server, and the second is performing table partitioning in conjunction with the index clustering on the fact tables. The latter has been performed as outlined in Figure 4a, with the result observed in Figures 4b, 4c, and 4d.
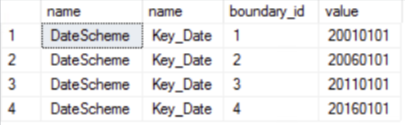
The partition has been created using a partition function and a partition scheme that can be applied against both fact tables on the date key. The scheme must be created before the function is created. Once both are created the table can be partitioned. As FinanceDW is a new data warehouse schema, there was no necessity to drop any clustered indexes against the date key, meaning the index can be created directly against these columns as shown in Figure 4a. The vertical partitioning against the date column has been split into four sections as groups of five years covering the total period directly relating to the data set.
In addition to the partitions and clustered indexes against the date dimension DateKey column in the two fact tables, additional non-clustered indexes have been created against the fact tables and the sales representative dimension table. The fact tables include non-clustered indexes against the relationship columns that are linked to the dimension tables, which would ordinarily be classified as foreign key relations. In the sales representative dimension table, a non-clustered index has been created against the first and last names of the sales representatives, as these are most likely to be searched for querying and data analytics. However, it is recognised that given the relatively small size of this table, the effect this is likely to have on overall performance is expected to be minimal.
-- Create partitions
drop procedure if exists create_partitions
go
create procedure create_partitions
as
begin
drop partition scheme DateScheme;
drop partition function Key_Date;
drop index if exists idx_Fact_SO_Date on FactSaleOrder;
drop index if exists idx_Fact_SP_Date on FactSalePerformance;
-- Partition on datekey split into 4 five year intervals
create partition function Key_Date (int)
as range right for values ('20000101', '20050101', '20100101', '20150101');
create partition scheme DateScheme
as partition Key_Date ALL TO ([primary]);
-- Create Partition on FactSalePerformance
create clustered index idx_Fact_SP_Date on FactSalePerformance(DateKey)
with (statistics_norecompute = off, ignore_dup_key = off,
allow_row_locks = on, allow_page_locks = on)
on DateScheme(DateKey);
-- Create Partition on FactSaleOrder
create clustered index idx_Fact_SO_Date on FactSaleOrder(DateKey)
with (statistics_norecompute = off, ignore_dup_key = off,
allow_row_locks = on, allow_page_locks = on)
on DateScheme(DateKey)
end;
go
-- >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
-- Execute create partitions procedure
exec create_partitions;
go
-- >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
-- View Partitions
select
ps.name,
pf.name,
boundary_id,
value
from sys.partition_schemes ps
inner join sys.partition_functions pf ON pf.function_id=ps.function_id
inner join sys.partition_range_values prf ON pf.function_id=prf.function_id;
go
exec sp_helpindex 'FactSalePerformance';
go
exec sp_helpindex 'FactSaleOrder';
go


Recovery Model
Recovery models in SQL Server control how transactions are logged, the type of available restore operations, and whether a transaction log is allowed to be backed up or needs to be backed up. There are three recovery models available:
- Simple
- Full
- Bulk-logged
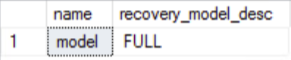
The FinanceDW data warehouse uses the full recovery model by default. Should this not meet the technical requirements the data warehouse can be switched to an alternate recovery model using a alter database query, for example setting model set recovery simple.
A review of the three recovery models allowed a determination to be made, indicating that the default full model was suitable for the FinanceDW data warehouse. The simple model was deemed to be insufficient as it prioritises disk space at the expense of log backups, meaning changes since the last backup are exposed to loss. The full model in comparison allows recovery to a point in time resulting in limited exposure to loss.
The bulk-logged model is an adjunct of the full model, however, this model reduces log space by limiting logs against bulk operations. If damage occurs to the log since the most recent backup there will be exposure to loss. Additionally, recovery can only be performed to the end of a performed backup, the model does not support point in time recovery.
The SQL statement used to confirm the full recovery model in the FinanceDW data warehouse can be viewed in Figure 5a, the result of which is shown in Figure 5b.
-- >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
-- Create Recovery Model
-- View recovery model
select
name,
recovery_model_desc
from
sys.databases
where name = 'model';
go
Blaha, M. (2016, June 15). Data Warehouses Should Stage Source Data. DATAVERSITY. https://www.dataversity.net/data-warehouses-stage-source-data/
cawrites. (n.d.-a). Recovery Models (SQL Server)—SQL Server. Retrieved October 22, 2021, from https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/recovery-models-sql-server
cawrites. (n.d.-b). Set database recovery model—SQL Server. Retrieved October 22, 2021, from https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/view-or-change-the-recovery-model-of-a-database-sql-server
Multidimensional Warehouse (MDW). (n.d.). [Pstopic]. Retrieved October 17, 2021, from https://docs.oracle.com/cd/E41507_01/epm91pbr3/eng/epm/penw/concept_MultidimensionalWarehouseMDW-9912e0.html
Surrogate Key in Data Warehouse, What, When and Why. (n.d.). Data Integration Solutions. Retrieved October 17, 2021, from http://www.disoln.org/2013/11/Surrogate-Key-in-Data-Warehouse-What-When-Why-and-Why-Not.html