Journal #Twelve [DAT601] - SQL Server - Indexes
![Journal #Twelve [DAT601] - SQL Server - Indexes](/assets/images/DAT601-J12.jpeg)
SQL Server - Indexes
JOURNAL #TWELVE [DAT601]
Learning Summary
Large databases by their nature can take time and resources to search through tables, this becomes more apparently if there are a huge number of rows contained within a table.
SQL Server has a structure built into it that can greatly speed up this process known as indexing. There are two types of indexes in SQL Server, clustered and non-clustered.
Clustered Indexes
The clustered index method utilises a sorted structure to store the data rows. The storing of data rows is done on the key values, each table has one clustered index meaning that the data rows are sorted in one order.
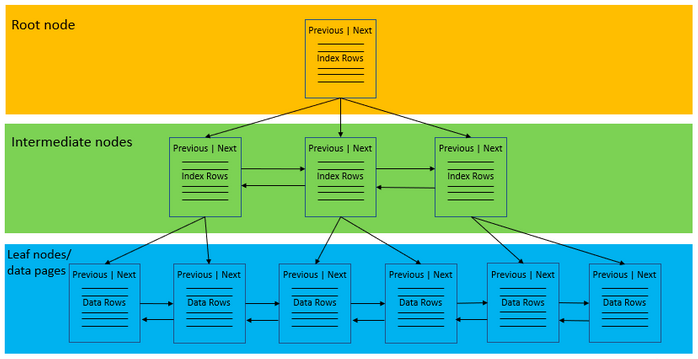
Tables with a clustered index are referred to as clustered tables. The structure is referred to as a B-tree or ‘balanced tree’. The structure can be best described as an upside-down tree with the leaves at the bottom, referred to as the ‘leaf node’ and the roots at the top referred to as the ‘root node’. In between the two are the intermediate levels.
The index pages are stored at the root and intermediate levels and these hold the index rows, at the leaf level are the data pages making up the underlying tables.
The following diagram shows the structure of the clustered index:
Non-Clustered Indexes
A non-clustered index operates differently to a clustered index, its aim is the same in that it is designed to speed up the retrieval of data, however it does the sorting and storing separately from the table rows.
It achieves its aim by copying specific data from columns in the table and then links that data to the associated table. Despite the differences a non-clustered index also uses a B-tree structure, the difference between the two index methods can be compared when looking at the following non-clustered diagram:
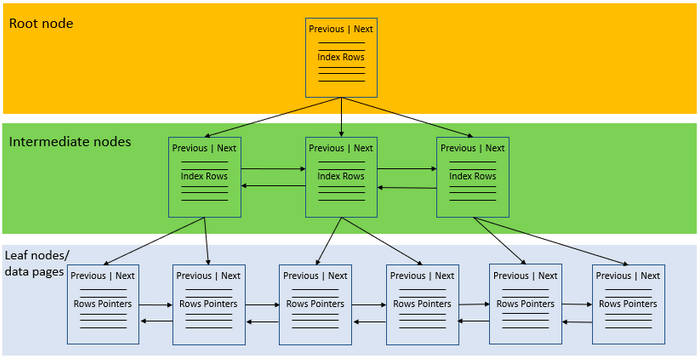
In addition to storing the index values, the nodes at the leaf level also store row pointers to the data rows that contain those key values. In a non-clustered structure, a table can have one or many non-clustered indexes with indexes including one or many columns of the table.
A non-clustered table can have a clustered table underlying it meaning that the row pointer is the index key in the clustered table.