Journal #Five [DAT601] - Normalisation
![Journal #Five [DAT601] - Normalisation](/assets/images/j5header.PNG)
Normalisation
JOURNAL #FIVE [DAT601]
Learning Summary
EXPLAINING NORMALISATION [ALL THE WAY TO 5NF]
A Brief Introduction
Normalisation is a database design technique that splits larger tables into smaller ones for the purpose of reducing redundancy and dependency of data. The benefits of normalisation include the elimination or useless, or redundant data and to ensure the data stored is done so in a logical manner.
The concept of normalisation was proposed by Edger Codd who introduced the first normal form, then proceeded to develop the second and third normal forms. The Boyce-Codd normal form was developed later in conjunction with Raymond F. Boyce.
The process of normalisation is carried out through the use of established rules, moving the data stored in the tables from a unordered collection towards an optimised format by adhering to the established rules at each normal form stage.
There are three commonly used normal forms in database normalisation. First to third normal form start the process and in practice, are often enough for most databases to achieve best results. However, this explanation deals with normalisation through unnormalised form to fifth normal form:
WHAT
Defining Normalisation
Unnormalised Form (UNF)
The unnormalised form provides the basic data the will be held in the database and represents the start the normalisation process. This does not have to come in a tradition table layout but could be a spreadsheet, equally an unnormalised form could be a report, ID Card, invoice, purchase order or some other kind of business document that has been identified as necessary to develop a database.
The takeaway of unnormalised forms is that it is a collection of data and information that is not ordered in a structured way, but must still be developed into a database of tables containing columns.
The unnormalised form can be represented by a table that orders the information from a business document, something the database designer has deemed relevant as in the below example. At this level of normalisation the table will most likely contain a repeating group or groups.
At this stage the only considerations made are:
- Column headings for each item of data to be stored in the system
- Introduction of acceptable naming conventions
- Remove any domains that are calculated or derived fields
- Select a suitable key or set of keys that for a unique identity to be the Primary or Composite Key
Example data (UNF):
First Normal Form (1NF)
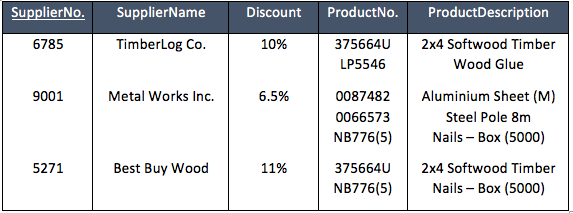
We begin the normalisation process at first normal form, but only after analysing the data in unnormalised form. The first step in the normalisation process looks to separate the data where repeating values have been identified.
We can identify repeating values as data that directly relates to the primary key (PK), in our example case we have data repeating in the following domains (ProductNo, ProductName). In each instance we see the values repeating themselves across the tuples. The repeating values do however, mean that the field relating to an individual row and column is singular in nature.
In this form an argument could be made that the data is workable. In my career I have seen many instances where spreadsheets have operated in this way and used on a daily basis. However there are drawbacks when discussing database design, mainly that in large databases the storage capacity required would be huge, and searches become unnecessarily time consuming.
The rules that apply from UNF to 1NF are as follow:
- If the data is of sufficiently high quality, identify the repeating data
- Take out the domains that repeat to create a new table, but leave behind a copy of the PK in the original table
- Identify and record a new PK in the original table as the previous PK is no longer unique, being the PK of the newly created table
- All values must be atomic value
Example data (1NF):
Second Normal Form (2NF)
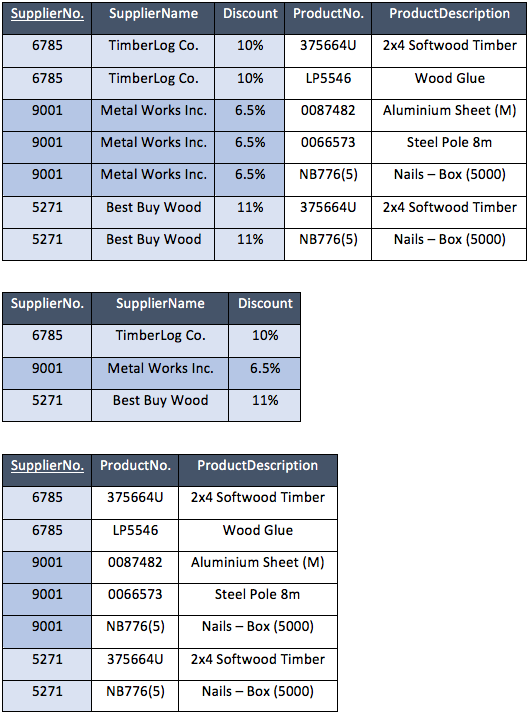
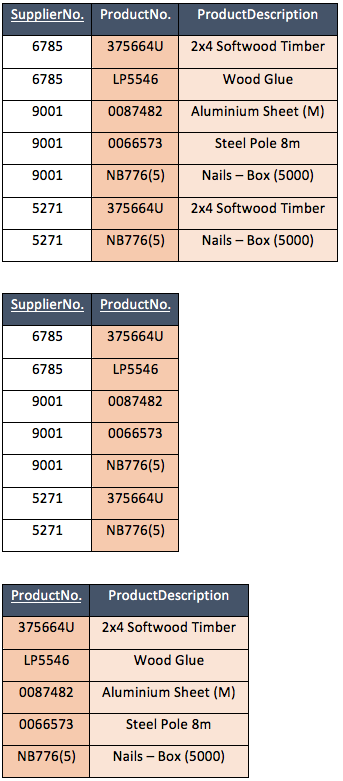
The purpose of the 2NF is to identify and remove any partial dependencies that currently exist on the PK. In order to begin this process the relation must be in 1NF. In effect what we are doing is ensuring that the database is not storing any more data than is necessary after removing repeating data in the 1NF.
In the example below we can see that for every ProductNo we are also storing the ProductDescription. The process of taking the 1NF to 2NF is to remove these partial dependencies and therefore reduce the duplicates, and any subsequent pressure on database storage capacity.
The process of transforming the relational into 2NF means taking the partial dependency ProductDescription, out of the table and placing it in a new relation with its functional dependency. In this case ProductNo becomes the PK of the newly created table and a FK, and CK of the original table.
Example data (2NF):
Third Normal Form (3NF)
The purpose of the 3NF is to identify and remove the transitive dependencies that currently exist. If the attribute has a transitive dependency or dependencies, these will need to be removed into their own relation. In order to begin this process the relation must be in 2NF.
The challenge is to remove those attributes that are more dependent on another attribute then they are on the PK of the relation. So if it is better for the attribute to step on another attribute, before getting to the PK, then this is a transitive dependency.
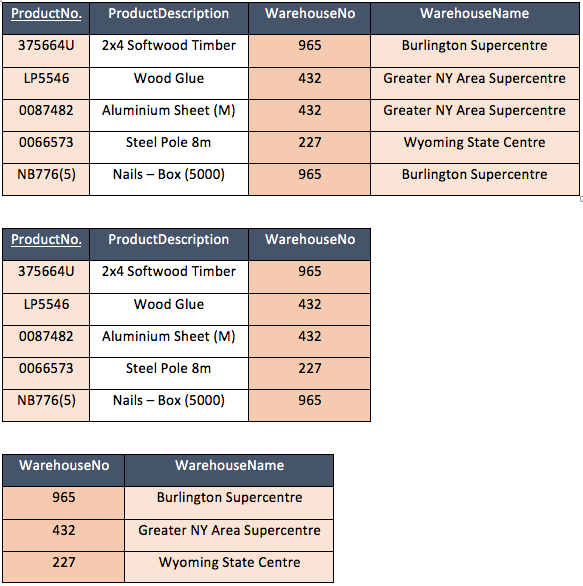
In the example below we can see WarehouseName is transitively dependent on ProductNo through WarehouseNo. So although WarehouseName could be dependent on ProductNo, it is more dependent on WarehouseNo.
The process to 3NF is firstly removing the WarehouseName attribute from the current relation to create a new table, WarehouseNo becomes the PK of this new table and is now the FK of the original table.
Example data (3NF):
Boyce-Codd Normal Form (BCNF) - (3.5 Normal Form)
The BCNF looks at rules surrounding prime attributes or super keys, and non-prime attributes. Normalisation has, up until now seen non-prime attributes depend on:
- prime attributes i.e. functional dependency
- part of a primary key i.e. partial dependency
- other non-prime attributes i.e. transitive dependency
BNCF looks at situations whereby a non-prime attribute derives a prime attribute, this type of occurrence must be resolved for the relation to be transformed to BCNF.
There are two conditions that must be satisfied for BCNF:
- The requirements of 3NF must be met
- Any dependency e.g. if ‘A’ is dependent on ‘B’, then ‘B’ must be a super key or prime attribute, it cannot be a non-prime attribute
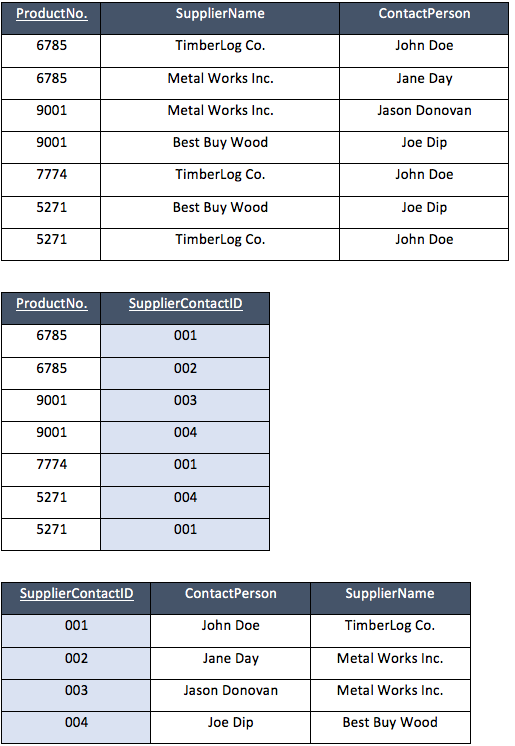
In the following BCNF example we can take ProductNo and SupplierName to determine the other table column (or columns where applicable). In addition because ContactPerson relates to just one SupplierName, we can use this domain to determine the SupplierName.
The dependencies in the table are:
- (ProductNo, SupplierName) can determine ContactPerson and;
- ContactPerson can determine SupplierName
This means there are no partial or transitive dependencies. What we are left with however is ProductNo and SupplierName as a composite key, making the SupplierName a prime attribute of ContactPerson, and a non-prime attribute (one that is not a super key) cannot derive a prime attribute (super key).
This must be resolved, so we need to separate the table in order to satisfy the rules of BCNF.
Example data (BCNF):
Fourth Normal Form (4NF)
The purpose of the 4NF is to ensure the table does not contain any multi-valued dependency. There are three conditions that determine whether there are multi-valued dependencies in the table:
- where ‘B’ is dependent on ‘A’, if the value of ‘A’ is a single value, but ‘B’ has multiple values, then there may be multi-valued dependency in the table
- in addition, for the table to have multi-valued dependencies there should be a minimum of three columns, if there is less than three then the problem can be resolved by adding multiple rows to ‘A’
- plus, where a table is T(A, B, C), if the situation includes a multi-valued dependency between ‘A’ and ‘B’, then columns ‘B’ and ‘C’ must be independent of each other
Multi-valued dependency will exist in a table if all the above conditions are met.
There are two conditions that must be satisfied for 4NF:
- The requirements of BCNF must be met
- There must be no multi-valued dependencies within the table
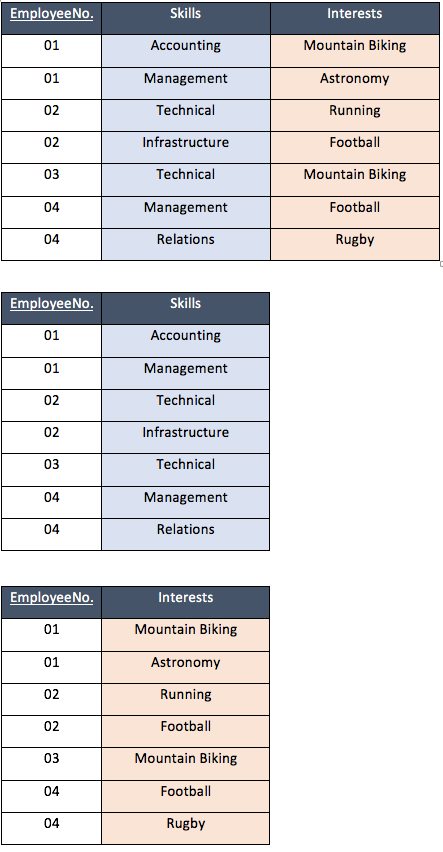
In the example table we can see that EmployeeNo shows skills held by that employee, and there interests outside of the work environment. The skills obtained and interest both relate to the EmployeeNo but not to each other.
In order to resolve the issue of multi-valued dependency we must separate these attributes into two individual tables using EmployeeNo as the unique identifier in both tables. These kind of multi-valued dependencies occur because of poor database design.
Example data (4NF):
Fifth Normal Form (5NF)
The purpose of the 5NF is to split out the table to further eliminate any anomalies or redundancies within the data. The key here is to ensure that if we join the tables back there should be no loss of data, nor should there be a creation of new records that would not be correct information.
If this type join dependency existed as a result of splitting the tables, then new entities would be created unnecessarily or data could be lost.
There are two conditions that must be satisfied for 5NF:
- The requirements of 4NF must be met
- There must be no join dependencies within the table, meaning the table cannot be decomposed further without creating a loss
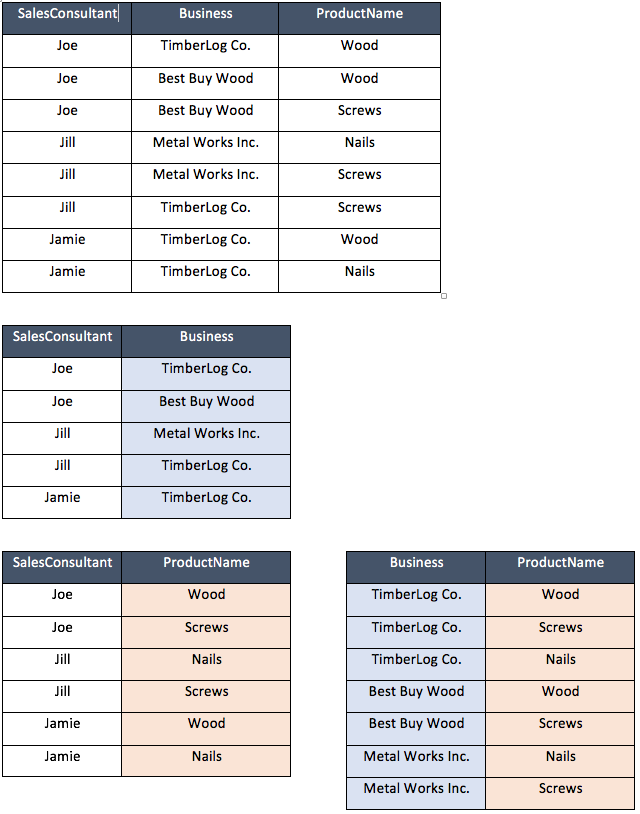
In the example below we can see the loss of data and the creation of new, but inaccurate records as a result of decomposing the relation into three tables.
What we have caused by doing this is to create a situation whereby:
- Joe works for TimberLog Co and Best Buy Wood, if we join this to the table
- stating that Joe sells both wood and screws and
- join this to the table showing both TimberLog Co and Best Buy Wood sell wood and screws we have produced a set of relations containing information that Joe sells wood and screws from both TimberLog Co and Best Buy Wood.
This however is not the case, we have lost the data stating that Joe only sells wood from TimberLog Co, and in reverse added new data stating that Joe sells screws from TimberLog Co, which is not the case.
It should be noted that 5NF is mainly an academic pursuit, it is not commonly used by database designers.
Example data (5NF):
WHY
The normalisation process is extremely important in database design. It prevents data anomalies in the system, which is the storing of data in two places and therefore maintains data integrity.
Simply put it means that one piece of data ,if changed, will change the data elsewhere in the database. Without normalisation a user would be able to change a piece of data in one place, but it wouldn’t change elsewhere in the database, leading to conflicts and confusion.
It’s easy to see how problematic this could become in a business system. So we normalise in order to mistake-proof the database, producing consistent data across that can be relied upon and trusted.
What normalisation also does is to reduce data redundancy, meaning the database requires less storage capacity to maintain.
HOW
The process of normalisation can be achieved by following the steps as outlined in this Journal.
I found that the best way to fully understand each normal form was to create my own example relations and apply the techniques to the data sets produced.